Sentiment Classifier on IMDB reviews¶
In this notebook, we build multiple neural network models to classify IMDB movie reviews by their sentiment.
Load dependencies¶
import numpy as np
import itertools
from matplotlib import pyplot as plt
import pandas as pd
from sklearn.metrics import accuracy_score,confusion_matrix
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
# set random seed for reproducibility
np.random.seed(1234)
import warnings
warnings.filterwarnings('ignore')
Load data¶
# load the dataset but only keep top 10000 words
top_words = 10000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words)
print('There are {} in training and {} records in IMDB movie test set.'.format(len(X_train), len(X_test)))
IMDB moive reviews have been preprocessed, and each review is encoded as a list of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer "3" encodes the 3rd most frequent word in the data. This allows for quick filtering operations such as: "only consider the top 10,000 most common words, but eliminate the top 20 most common words".
print('First record:')
X_train[0:1]
print('Our label to classify sentiment is negative-0 and positive-1')
y_train[0:10]
Preprocess data¶
# truncate and pad input sequences to make all reviews equal length
max_review_length = 500
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length)
df_accuracy = pd.DataFrame(columns=['Model', 'Accuracy'])
# define input vector size for the first dense layer
embedding_vector_length = 32
Functions to predict sentiment and note accuracy¶
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print('Normalized Confusion Matrix:')
print(cm)
def predict(model, name):
y_pred = model.predict_classes(X_test)
acc = accuracy_score(y_test, y_pred)
cfs = confusion_matrix(y_test, y_pred)
plt.figure()
class_names = ["Positive", 'Negative']
plot_confusion_matrix(cfs, classes=class_names, title=name)
return acc
# function to evaluate model and record acurracy
def evalmodel(this_model, name):
global df_accuracy
scores = this_model.evaluate(X_test, y_test, verbose=0)
test_accuracy = predict(this_model, name)
df_accuracy = df_accuracy.append({'Model':name,
'Accuracy': scores[1]
}, ignore_index=True)
return df_accuracy
Design neural network architecture for Sequential Classification¶
LSTM¶
model_lstm = Sequential()
model_lstm.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length))
model_lstm.add(LSTM(100))
model_lstm.add(Dense(1, activation='sigmoid'))
model_lstm.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model_lstm.summary())
%%time
model_lstm.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=3, batch_size=64)
%%time
evalmodel(model_lstm, 'LSTM')
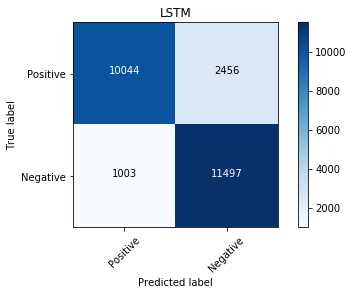
LSTM with Dropout¶
from keras.layers import Dropout
model_lstm_dropout = Sequential()
model_lstm_dropout.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length))
model_lstm_dropout.add(Dropout(0.2))
model_lstm_dropout.add(LSTM(100))
model_lstm_dropout.add(Dropout(0.2))
model_lstm_dropout.add(Dense(1, activation='sigmoid'))
model_lstm_dropout.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model_lstm_dropout.summary())
%%time
model_lstm_dropout.fit(X_train, y_train, epochs=3, batch_size=64)
%%time
evalmodel(model_lstm_dropout, 'LSTM with Dropout')
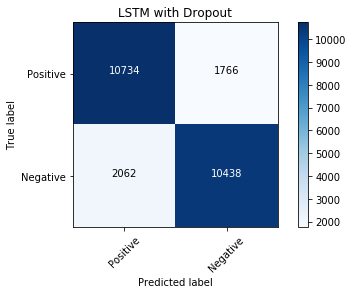
LSTM with double drop out, drop out between layers and drop out within layers of LSTM¶
model_dropout_recurrentdropout = Sequential()
model_dropout_recurrentdropout.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length))
model_dropout_recurrentdropout.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model_dropout_recurrentdropout.add(Dense(1, activation='sigmoid'))
model_dropout_recurrentdropout.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model_dropout_recurrentdropout.summary())
%%time
model_dropout_recurrentdropout.fit(X_train, y_train, epochs=3, batch_size=64)
%%time
evalmodel(model_dropout_recurrentdropout, 'LSTM with Dropout on LSTM and the Recurrent units as well')
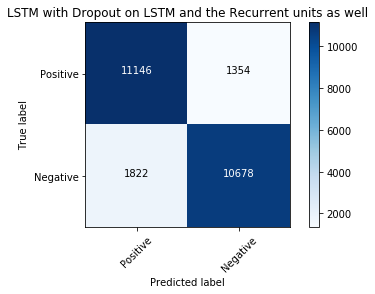
LSTM and Convolutional Neural Network¶
from keras.layers import Flatten
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
model_lstm_cnn = Sequential()
model_lstm_cnn.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length))
model_lstm_cnn.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu'))
model_lstm_cnn.add(MaxPooling1D(pool_size=2))
model_lstm_cnn.add(LSTM(100))
model_lstm_cnn.add(Dense(1, activation='sigmoid'))
model_lstm_cnn.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model_lstm_cnn.summary())
%%time
model_lstm_cnn.fit(X_train, y_train, epochs=3, batch_size=64)
%%time
evalmodel(model_lstm_cnn, 'LSTM and CNN')
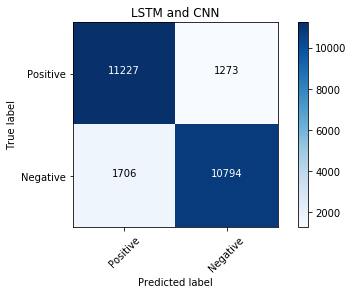
LSTM, CNN with Flatten and FCN¶
# add flatten and FCN - fully connected network to optimize the model further
model_cnn_flatten_fcn = Sequential()
model_cnn_flatten_fcn.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length))
model_cnn_flatten_fcn.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu'))
model_cnn_flatten_fcn.add(MaxPooling1D(pool_size=2))
model_cnn_flatten_fcn.add(Flatten())
model_cnn_flatten_fcn.add(Dense(250,activation='relu'))
model_cnn_flatten_fcn.add(Dense(1, activation='sigmoid'))
model_cnn_flatten_fcn.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model_cnn_flatten_fcn.summary())
%%time
model_cnn_flatten_fcn.fit(X_train, y_train, epochs=3, batch_size=128)
%%time
evalmodel(model_cnn_flatten_fcn, 'LSTM, CNN w/ Flatten, FCN, Batch Size-128')
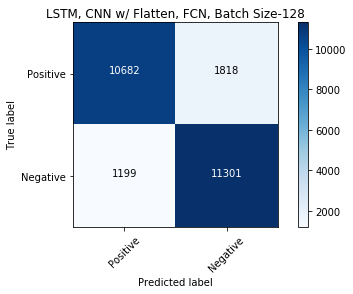
%%time
model_cnn_flatten_fcn.fit(X_train, y_train, epochs=3, batch_size=64)
%%time
evalmodel(model_cnn_flatten_fcn, 'LSTM, CNN w/ Flatten, FCN, Batch Size-64')
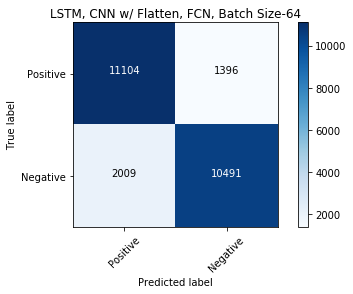
We have built model with one LSTM layer, added dropout on LSTM layer and recurrent input layer, then tried CNN, CNN with Flatten and Fully Connected Network. The training times are 18, 15, 25, 6, 1 minutes respectively. For an accuracy of 88%, last model with 1 minute training time seems to be better for our sentiment analysis.